

Snowflake-Native by Design
Built 100% inside Snowflake, π-Snow eliminates external dependencies and leverages the platform's full capabilities for security, performance, and governance.
At πby3, our Data Engineering practice helps enterprises build scalable, reliable data platforms for analytics, AI, and GenAI. We cover the full data engineering lifecycle from ingestion and transformation to orchestration, validation, and modernization enabling governed, production-ready data foundations.
With a strong focus on cloud-native, performance-optimized architectures, we design resilient data pipelines that scale efficiently. Where Snowflake is the core platform, we specialize in Snowflake-native data engineering, running pipelines entirely within Snowflake to maximize performance, security and elasticity.
To accelerate this capability at scale, πby3 offers π-Snow, our Snowflake-native data engineering accelerator suite.
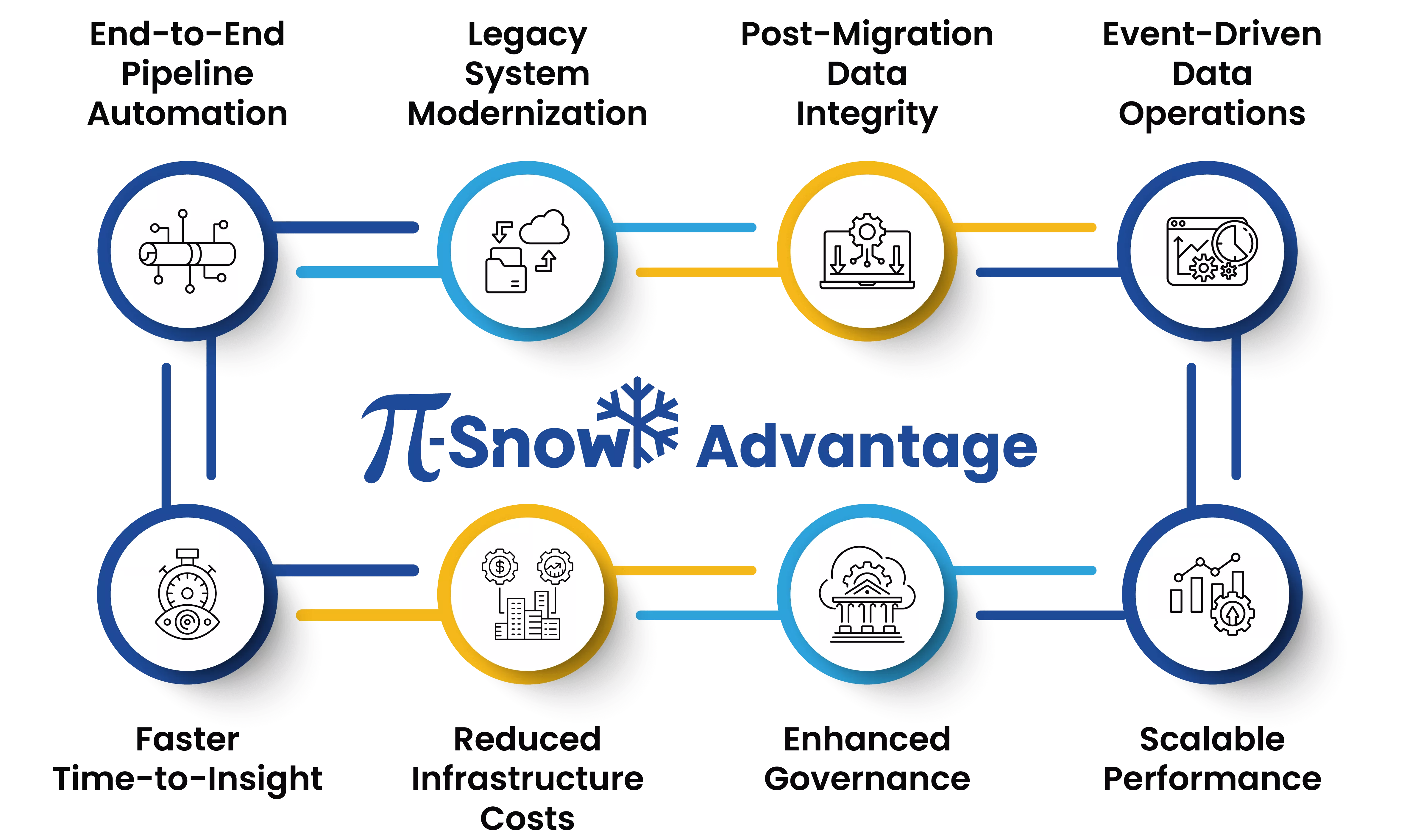
A Snowflake-native data engineering suite for ingestion, modernization, orchestration and validation
To truly harness Snowflake's power, your data engineering lifecycle must operate natively within it. π-Snow is πby3's Snowflake-native accelerators automating ingestion, transformation, orchestration, and validation entirely inside Snowflake.
Built 100% within Snowflake's architecture, π-Snow eliminates external tool dependencies and delivers automation-driven, high-performance data operations that scale with your enterprise needs.

Create integration complexities, requiring constant maintenance across multiple platforms and vendors.
Introduce latency, security gaps and unnecessary infrastructure overhead that counteracts cloud efficiency.

Consume engineering hours on repetitive tasks, from data validation to pipeline scheduling, slowing time-to-insight.

Emerge when processing happens outside Snowflake, forcing data movement and degrading the platform's native optimization capabilities.

Multiply as data flows through external systems, making compliance tracking and audit trails increasingly complex.
Our suite comprises five purpose-built accelerators that work seamlessly together or independently, addressing every stage of your data engineering lifecycle:
π-Ingest automates data onboarding through intelligent metadata frameworks, eliminating custom scripts and manual mapping. Whether handling full or incremental loads, it delivers fast, scalable and compliant ingestion entirely within Snowflake.
Learn More
Turbo-π accelerates platform modernization by converting legacy ETL pipelines into optimized, cloud-native SQL stored procedures with full pushdown execution. It transforms legacy ETL transformation logic into high-performance Snowflake operations without requiring complete rewrites.
Learn More
π-Flow brings intelligent orchestration directly into Snowflake, replacing external schedulers with native task management. It converts complex job dependencies into event-driven workflows that trigger automatically based on time, data arrival or upstream completion.
Learn Moreπ-Recon automates data reconciliation and validation after migrations or transformations, ensuring accuracy and completeness without manual verification. Using advanced statistical methods, it handles heterogeneous sources and complex data structures at scale.
Learn More
π-QLens delivers automated, metadata-driven data quality monitoring entirely within Snowflake continuously measuring completeness, validity, uniqueness, consistency, freshness and volume across enterprise datasets. It converts technical rule results into business trust scores, giving both engineers and stakeholders
Learn More


At πby3, we recognize that every enterprise's data engineering maturity and requirements differ. Our approach to π-Snow implementation is consultative and tailored to your specific context.
Whether you're modernizing a legacy platform, scaling current Snowflake operations, or building greenfield data infrastructure, our team works with you to identify the right accelerators and deployment strategy.