
CRM Salesforce to Snowflake Data Integration for a Leading Financial Major Using the Proprietary π Ingest Solution
Replacing a Fragmented, Costly Ingestion Architecture with a Unified, Scalable, and Snowflake-Native Data Pipeline
Overview
Data integration is only as reliable as the architecture beneath it. When pipelines fail frequently, costs scale unpredictably, and reports cannot be trusted to reflect current data analytics stops being an asset and starts being a liability.
A leading financial major was facing exactly this situation. Its Salesforce CRM to Snowflake data integration relied on a fragmented architecture of multiple tools and custom scripts that delivered frequent pipeline failures, inconsistent data quality, mounting licensing costs, and reporting delays that left business users without timely access to the data they needed.
We proposed the adoption of its proprietary accelerator π Ingest a Snowflake-native, end-to-end ingestion and transformation platform designed to replace the fragmented architecture with a unified, scalable, and cost-effective data integration pathway.
The customer moved forward, and the migration was executed through a structured two-phase cutover strategy delivering seamless data flow, uninterrupted business operations, and a defect-free production cutover.
The Challenges
- Frequent Data Pipeline Failures: High data volumes caused recurring infrastructure breakdowns and performance issues, directly undermining the reliability and scalability of the analytics platform.
- Fragmented and Inefficient Ingestion Framework: Data ingestion relied on multiple tools and custom scripts operating independently creating an inconsistent, difficult-to-maintain architecture with no centralized control.
- High Licensing and Maintenance Costs: Dependence on multiple external tools drove up licensing fees and ongoing maintenance overhead, inflating the Total Cost of Ownership (TCO) without commensurate business value.
- Complex Distributed Architecture: The ingestion framework was spread across Azure Data Factory (ADF) pipelines and custom scripts making data lineage tracing, debugging, and quality assurance consistently difficult.
- Slow Data Ingestion and Reporting Delays: Poorly designed pipelines caused slow data movement, resulting in reports and analytics not being refreshed on time leaving business users without access to current data when decisions needed to be made.
- Specialized Skill Dependencies: The breadth of tools in use created heavy reliance on a small number of skilled resources, limiting the organization's ability to scale teams, onboard new talent, and sustain operations confidently.
- High Development Effort Per Dataset: Onboarding each new Salesforce table required significant development effort making every addition time-consuming, costly, and difficult to justify at scale.
The Solution
The adoption of π Ingest established the foundation of a unified, efficient, and Snowflake-native data integration platform built to address every layer of the existing architecture's limitations.
- End-to-End Ingestion Pipeline: A single pipeline capable of handling full loads, incremental updates, and deleted records ensuring complete and reliable data coverage across all ingestion scenarios.
- Centralized Orchestration and Scheduling: Dependencies on ADF and Airflow were eliminated entirely through a centralized orchestration framework streamlining operations and significantly reducing coordination overhead.
- Automated Data Transformations: Transformations aligned with target Snowflake models were automated ensuring consistency, accuracy, and faster delivery of analytics-ready data.
- Real-Time Monitoring and Operational Dashboards: Built-in Snowflake-native logging and monitoring provided complete visibility into pipeline execution, performance metrics, and data volumes removing the need for disparate external monitoring solutions.
- Proactive Alerting: A real-time email notification system was implemented to alert relevant stakeholders and support teams at the onset of pipeline failures or anomalies enabling proactive rather than reactive incident management.
- Hypercare Support Model: A structured Hypercare support framework was established post-go-live to safeguard stability, optimise performance, and ensure seamless ongoing operations.
Migration Strategy: Two-Phase Cutover
To minimise risk and maintain operational stability throughout the transition, the migration was executed through a two-phase cutover strategy combined with a parallel run — safeguarding data integrity and ensuring a defect-free production cutover.
- Phase 1
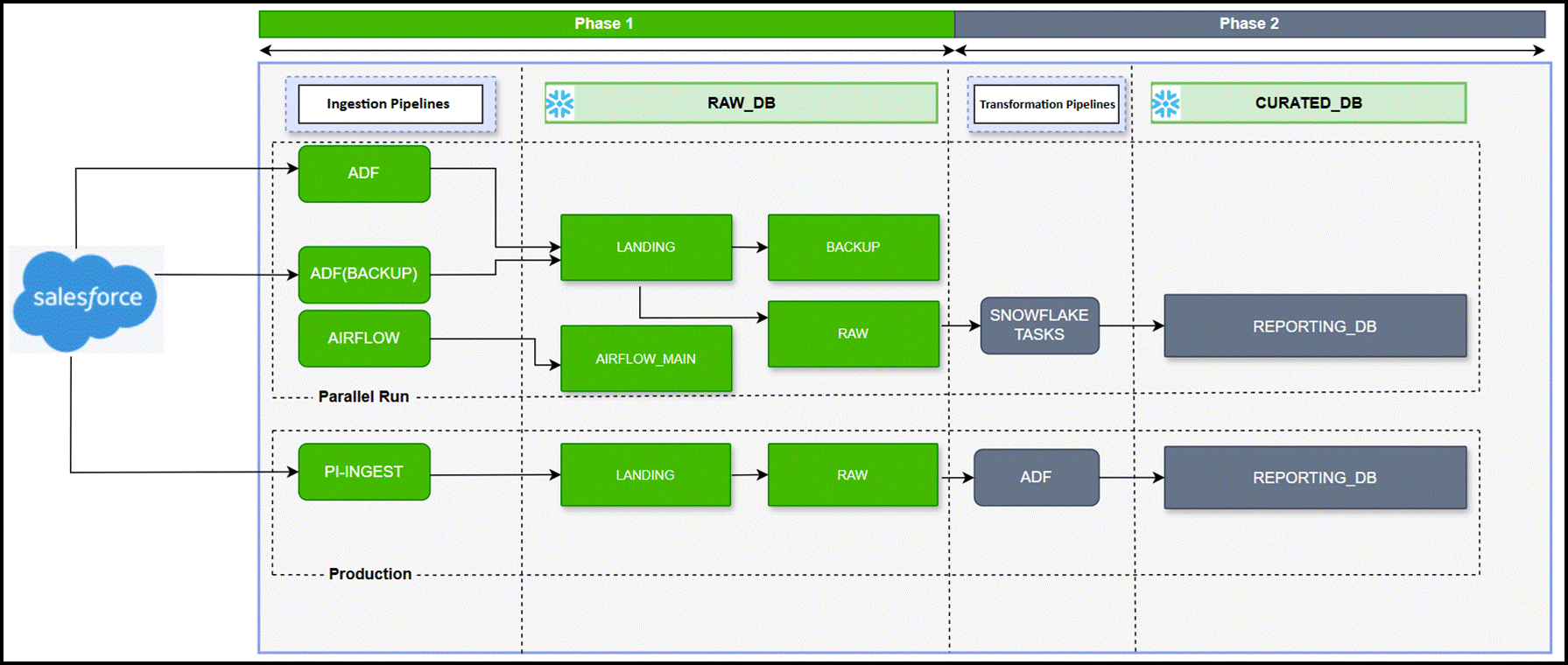
All Salesforce ingestion pipelines were migrated from Azure Data Factory (ADF) to π Ingest, leveraging Snowflake's native architecture for extraction and load processes.
The scope covered 45+ critical Salesforce tables including core entities such as Account, Contact, Opportunity, and Custom Objects processing a high volume of 3 million records daily.
Secure Authentication was implemented using Snowflake Secrets, ensuring credentials were never hardcoded at any point in the pipeline.
Built-in integrated logging and monitoring within π Ingest provided complete visibility into pipeline execution, performance metrics, and data volumes all within Snowflake, without external tooling dependencies. - Phase 2
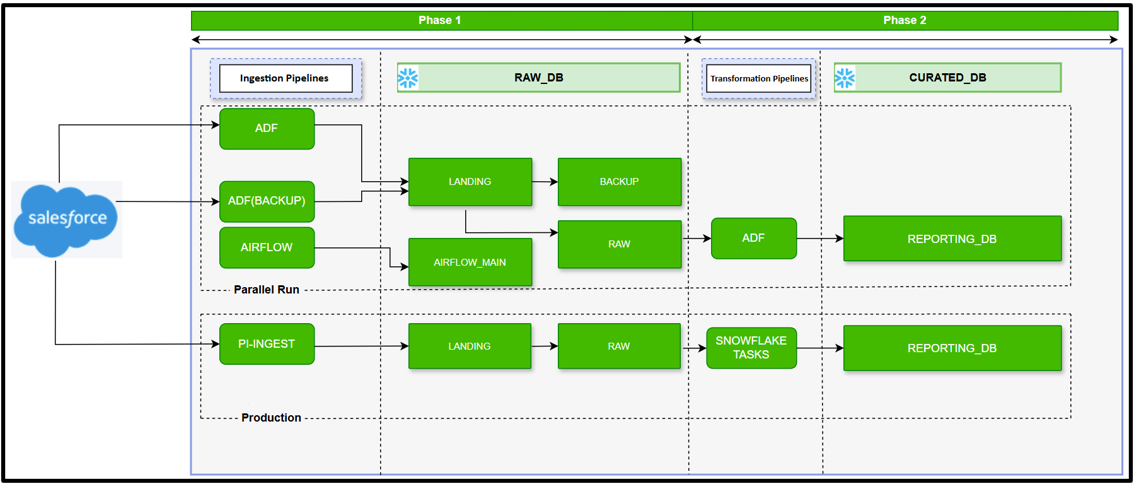
Following the successful ingestion cutover, 55+ stored procedures previously orchestrated through ADF were re-engineered and migrated to Snowflake Native Tasks responsible for data cleansing, aggregation, and business logic application.
Snowflake's native Directed Acyclic Graph (DAG) feature was leveraged to manage task dependencies ensuring transformations executed in the correct sequence while handling complex dependency chains efficiently.
Email notifications for transformation task execution were configured, delivering end-to-end operational transparency across both ingestion and transformation layers.
Technologies Used
- Snowflake: Cloud-native data platform serving as the unified foundation for ingestion, transformation, orchestration, monitoring, and storage
- π Ingest: End-to-end Snowflake-native ingestion and transformation platform replacing fragmented multi-tool architecture
- Salesforce CRM: Source system for CRM data ingestion across 45+ tables and 3 million daily records
- Snowflake Native Tasks and DAG: Orchestration of transformation pipelines with managed task dependencies
- Snowflake Secrets: Secure, hardcode-free authentication with Salesforce CRM
- Azure Data Factory (ADF): Legacy ingestion and transformation platform replaced through the migration
Impact Created
- 50% Reduction in Data Processing Time: By harnessing Snowflake's native architecture, π Ingest delivered a 50% reduction in data processing time enabling near real-time analytics and faster, more informed business decisions.
- Significant Cost Savings: Eliminating multiple third-party tools reduced both licensing fees and maintenance overhead substantially delivering a meaningfully lower Total Cost of Ownership (TCO) for the organization.
- Reusable Pipeline Framework: π Ingest introduced a reusable pipeline architecture significantly simplifying the onboarding of new datasets and tables and increasing engineering efficiency at scale.
- Improved Business Agility: Faster data availability and a streamlined development process enabled the enterprise to respond quickly to new reporting requirements and changing business needs a critical capability in the financial industry.
- Reduced Development Effort: The unified ingestion framework reduced the complexity of data integration, freeing engineers to focus on higher-value work rather than pipeline maintenance and debugging.
- Single Platform Dependency: End-to-end data engineering ingestion and transformation was consolidated onto a single platform, reducing technology and skills fragmentation across the data ecosystem.
Conclusion
Through a structured two-phase cutover migration and the deployment of π Ingest, the financial major successfully replaced a fragmented, costly, and unreliable data integration architecture with a unified, Snowflake-native pipeline that is efficient, scalable, and built for the future.
Pipeline failures, reporting delays, and inflated licensing costs were eliminated. In their place: near real-time analytics, a reusable ingestion framework, and a data ecosystem built on a single, governed platform.
The organization is now positioned to treat data as a strategic asset driving growth and sustaining competitiveness in a demanding and dynamic financial industry.
"Fragmented pipelines fragment decisions. A unified data platform does not just move data faster it moves the business forward."


